News Recommendation system at Riedia
Previous recommender system at Riedia
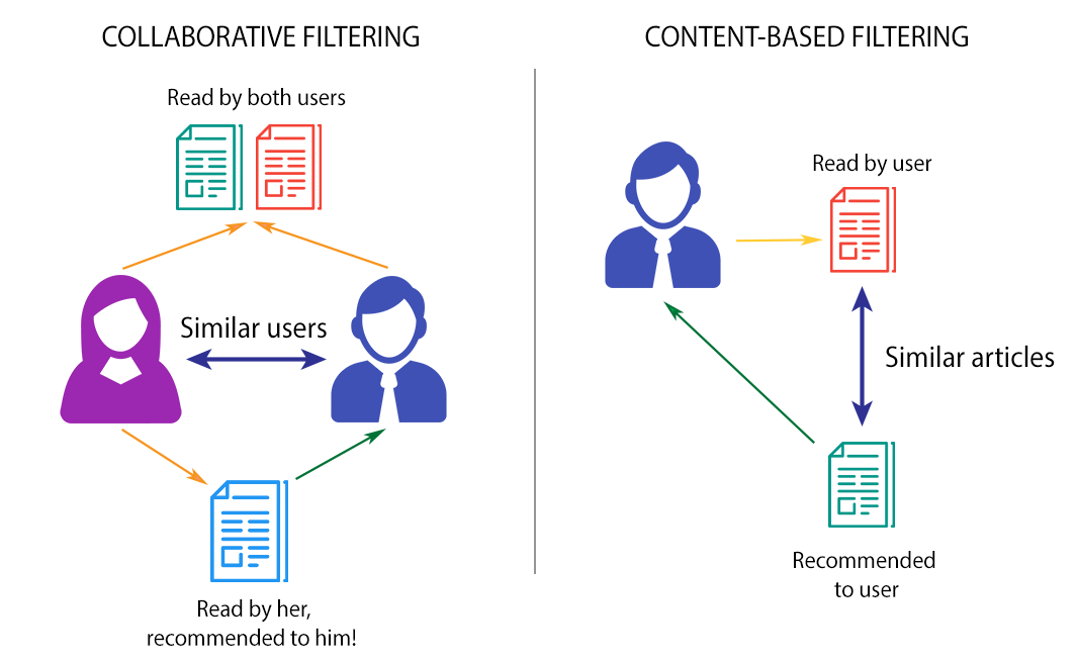
The team at Riedia in their start-up phase used a Content-based filter to find similar articles to the articles the user have read. The other type is by recommending news articles which a similar user have read to the user which is recommended. This approach is straight forward and have been the staple for recommender systems until deep learning. Therefore, wanted to explore this and they choose me to research this and come up with a solution.
New era of recommender systems leverage the dynamic nature of Deep learning
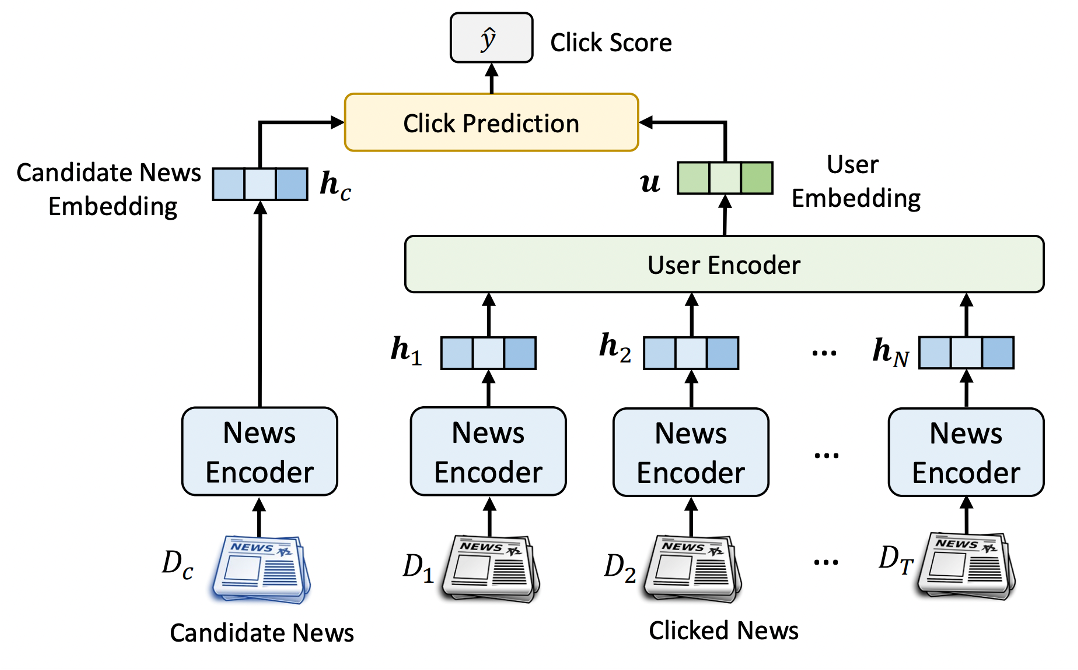
One type of news recommender system proposed by research is a click predictor. Probability over $0.5 := “Interested”$ while below $0.5 :=$ $”Not Interested”$. Furthermore, the model is feeded with articles which the user have read and one candidate news article. These articles are then encoded into a representation vector. How to represent these vectors could be done in multiple ways to embody the core structure and representation of the news article.
”Neural News Recommendation with Multi-Head Self-Attention”
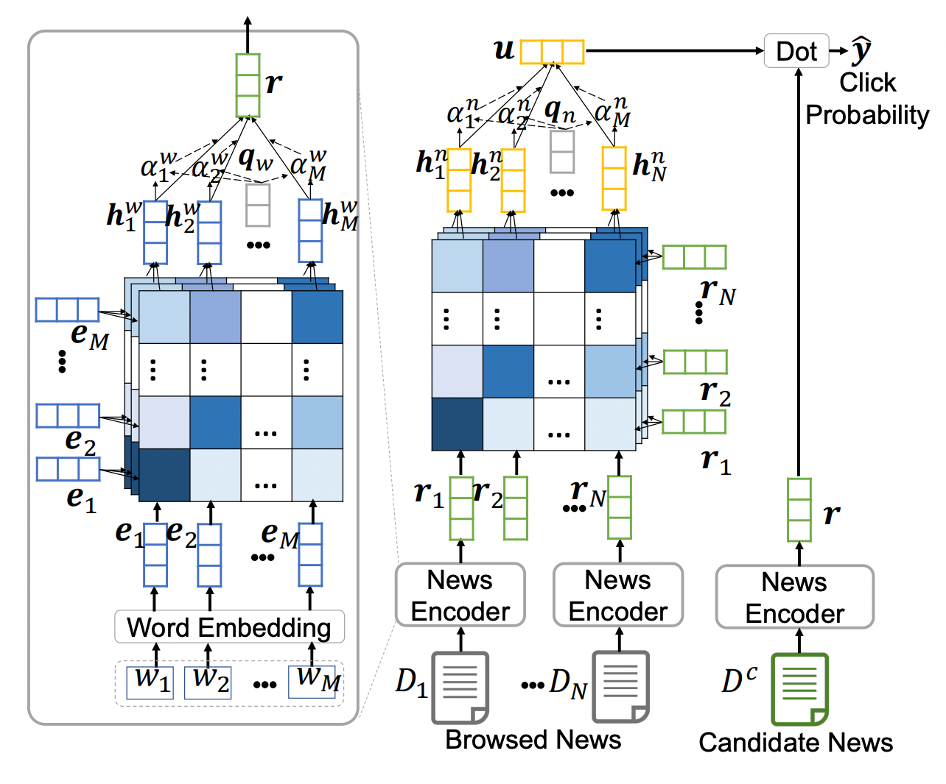
The model which was implemented was based on the paper “Neural News Recommendation with Multi-Head Self-Attention”. In this paper, a neural news recommendation approach called NRMS is proposed. The approach uses multi-head self-attention to model the interactions between words in news titles to learn news representations, and uses multi-head self-attention to capture the relatedness between news and user representations learned from browsed news. Additive attention is also applied to select important words and news.
More specifically, the NRMS approach for news recommendation includes three modules: a news encoder, a user encoder, and a click predictor. The news encoder is used to learn news representations from news titles, and contains three layers: word embedding, word-level multi-head self-attention network, and additive word attention network. The word embedding layer converts a news title from a sequence of words into a sequence of low-dimensional embedding vectors. The self-attention network captures interactions between words and learns contextual representations of words. Additionally, the user encoder module is a system that learns representations of users from the news articles they have browsed. It contains two layers. The first layer is a multi-head self-attention network that captures the interactions between related news articles browsed by the same user. The second layer is an additive news attention network that selects important news to learn more informative user representations. The system uses the relative importance of interactions between different news articles and selects the most informative news to model user interest. Lastly, the system predicts if the candidate news article is interesting or not using the dot-product between the user encoded embedding and the embedding of the candidate.
The MIND dataset

The dataset used to train the NRSM model where crawled data from Microsoft News used by The MIND competition to help improve the field of News Recommender systems. The dataset contained information both of the users’ behaviors and the news articles. This way it was possible to feed the user’s read articles to the User Encoder and the news articles to the News Encoders in the model.
Here is a sample of the data:
News data
This file contains news information including newsid, category, subcatgory, news title, news abstarct, news url and entities in news title, entities in news abstract. “One simple example:
N46466\tlifestyle\tlifestyleroyals\tThe Brands Queen Elizabeth, Prince Charles, and Prince Philip Swear By\tShop the notebooks, jackets, and more that the royals can't live without.\thttps://www.msn.com/en-us/lifestyle/lifestyleroyals/the-brands-queen-elizabeth,-prince-charles,-and-prince-philip-swear-by/ss-AAGH0ET?ocid=chopendata\t[{\"Label\": \"Prince Philip, Duke of Edinburgh\", \"Type\": \"P\", \"WikidataId\": \"Q80976\", \"Confidence\": 1.0, \"OccurrenceOffsets\": [48], \"SurfaceForms\": [\"Prince Philip\"]}, {\"Label\": \"Charles, Prince of Wales\", \"Type\": \"P\", \"WikidataId\": \"Q43274\", \"Confidence\": 1.0, \"OccurrenceOffsets\": [28], \"SurfaceForms\": [\"Prince Charles\"]}, {\"Label\": \"Elizabeth II\", \"Type\": \"P\", \"WikidataId\": \"Q9682\", \"Confidence\": 0.97, \"OccurrenceOffsets\": [11], \"SurfaceForms\": [\"Queen Elizabeth\"]}]\t[]
In general, each line in data file represents information of one piece of news:
[News ID] [Category] [Subcategory] [News Title] [News Abstrct] [News Url] [Entities in News Title] [Entities in News Abstract] ...
We generate a word_dict file to transform words in news title to word indexes, and a embedding matrix is initted from pretrained glove embeddings.
Behaviors data
One simple example:
1\tU82271\t11/11/2019 3:28:58 PM\tN3130 N11621 N12917 N4574 N12140 N9748\tN13390-0 N7180-0 N20785-0 N6937-0 N15776-0 N25810-0 N20820-0 N6885-0 N27294-0 N18835-0 N16945-0 N7410-0 N23967-0 N22679-0 N20532-0 N26651-0 N22078-0 N4098-0 N16473-0 N13841-0 N15660-0 N25787-0 N2315-0 N1615-0 N9087-0 N23880-0 N3600-0 N24479-0 N22882-0 N26308-0 N13594-0 N2220-0 N28356-0 N17083-0 N21415-0 N18671-0 N9440-0 N17759-0 N10861-0 N21830-0 N8064-0 N5675-0 N15037-0 N26154-0 N15368-1 N481-0 N3256-0 N20663-0 N23940-0 N7654-0 N10729-0 N7090-0 N23596-0 N15901-0 N16348-0 N13645-0 N8124-0 N20094-0 N27774-0 N23011-0 N14832-0 N15971-0 N27729-0 N2167-0 N11186-0 N18390-0 N21328-0 N10992-0 N20122-0 N1958-0 N2004-0 N26156-0 N17632-0 N26146-0 N17322-0 N18403-0 N17397-0 N18215-0 N14475-0 N9781-0 N17958-0 N3370-0 N1127-0 N15525-0 N12657-0 N10537-0 N18224-0
In general, each line in data file represents one instance of an impression. The format is like:
[Impression ID] [User ID] [Impression Time] [User Click History] [Impression News]
Results
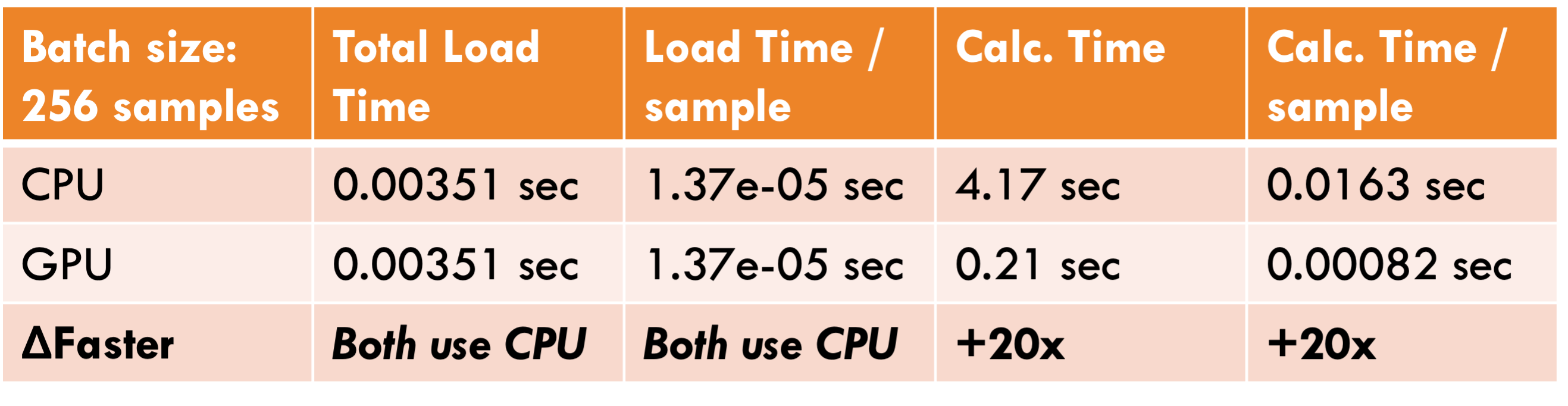
To quantify the results of the work I showed the team how the model performed from the test data of the MIND dataset. Likewise, to incorporate this model into production I had to also quantify the latency difference between using GPUs vs CPUs. The reason for this is that Riedia is a start-up with limited resources. We concluded that even though the CPU is much slower it has higher cost advantages. We therefore opted into a pre-calculated system, and not a Just-In-Time approach to not impact the user experience.
Measuring of accuracy
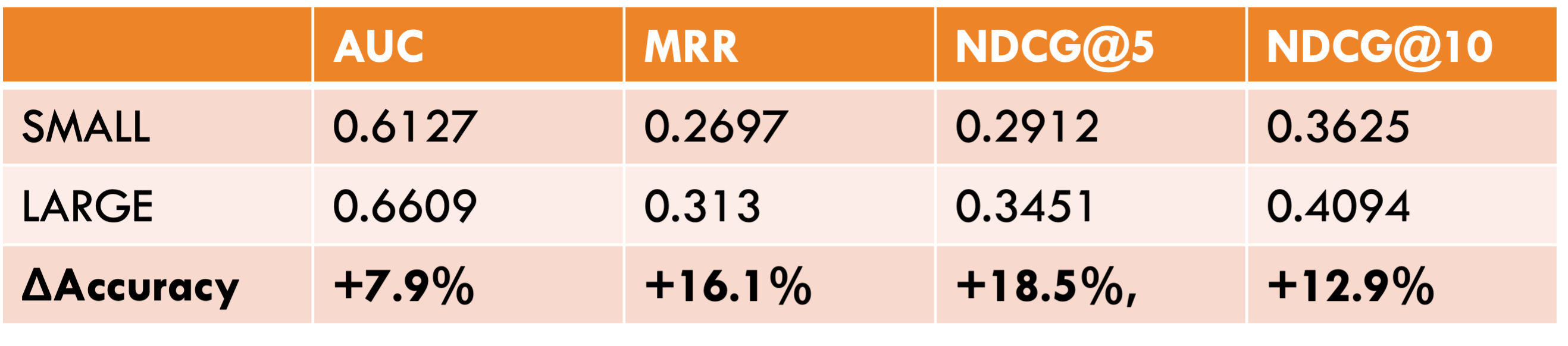
Calculating the latency using GPU and CPU for interference
Reflection
Working with machine learning in a dynamic start-up environment was incredibly fulfilling. The constant challenges and opportunities to use my creativity to the fullest made for a rewarding experience. From researching a news recommender system from scratch to implementing it in Riedia’s production, the journey was exhilarating and pushed my math and programming skills to new limits. It solidified my desire to work in similar environments where I am constantly pushed out of my comfort zone. The project was highly valuable and the team at Riedia was a pleasure to collaborate with. Overall, it was an incredible learning experience that has strengthened my PyTorch skills and math understanding and how to apply them to real-world solutions. 🙌